CS231n Convolutional Neural Networks for Visual Recognition
Translation alone can not extrapolate the understanding of geometric relationships to a radically new viewpoint, such as a different orientation or scale. On the opposite hand, people are very good at extrapolating; after seeing a new shape as soon as they’ll recognize it from a special viewpoint. One of the simplest methods to forestall overfitting of a community is to simply cease the training earlier than overfitting has had a chance to happen.
CNN Breaking US & World News
Since feature map dimension decreases with depth, layers near the enter layer will are likely to have fewer filters whereas higher layers can have extra. To equalize computation at every layer, the product of function values va with pixel place is saved roughly fixed throughout layers. Preserving more details about the input would require keeping the total number of activations (number of function maps occasions number of pixel positions) non-lowering from one layer to the following. ReLU is often preferred to other features because it trains the neural network several times sooner and not using a significant penalty to generalization accuracy. A parameter sharing scheme is used in convolutional layers to manage the variety of free parameters.
This ignores locality of reference in picture knowledge, each computationally and semantically. Thus, full connectivity of neurons is wasteful for purposes such as picture recognition which might be dominated by spatially local input patterns.
Since these networks are often educated with all out there information, one approach is to both generate new knowledge from scratch (if potential) or perturb current data to create new ones. For instance, input photographs could possibly be asymmetrically cropped by a few percent to create new examples with the identical label as the original. By avoiding coaching all nodes on all training data, dropout decreases overfitting.
The architecture and coaching algorithm were modified in 1991 and applied for medical picture processing and automated detection of breast most cancers in mammograms. The time delay neural network (TDNN) was launched in 1987 by Alex Waibel et al. and was the primary convolutional network, because it achieved shift invariance.
At Athelas, we use Convolutional Neural Networks(CNNs) for a lot extra than just classification! In this post, we’ll see how CNNs can be utilized, with nice outcomes, in picture instance segmentation. Dilated convolutions would possibly enable one-dimensional convolutional neural networks to successfully token price study time sequence dependences. Convolutions may be applied extra effectively than RNN-primarily based solutions, and they do not undergo from vanishing (or exploding) gradients.
The title “convolutional neural network” indicates that the community employs a mathematical operation calledconvolution. Convolutional networks are simply neural networks that use convolution instead of common matrix multiplication in no less than certainly one of their layers. One drawback with this approach is that ReLU neurons do not necessarily have any semantic meaning by themselves. Rather, it’s extra acceptable to think about a number of ReLU neurons as the premise vectors of some house that represents in image patches.
News of Holocaust dying camp killings becomes public for first time
They allow speech alerts to be processed time-invariantly. In 1990 Hampshire and Waibel launched http://www.hiddenhillsbend.com/crypto-sports/ a variant which performs a two dimensional convolution.
It comes with the drawback that the learning process is halted. neural nets, and as such allows for model http://ootbministries.com/will-monero-be-a-good-investment-in-2019/ mixture, at test time solely a single community must be tested.
![]()
Max pooling makes use of the utmost value from each of a cluster of neurons at the prior layer. Average pooling uses the average worth from every of a cluster of neurons at the prior layer. Meeting of the Institute of Electrical, Information and Communication Engineers (IEICE).
There are a number of non-linear capabilities to implement pooling among which max pooling is the most common. It partitions the input picture into a set of non-overlapping rectangles and, for each such sub-region, outputs the maximum.
They did so by combining TDNNs with max pooling to be able to notice a speaker unbiased isolated phrase recognition system. In their system they used a number of TDNNs per word, one for every syllable. The outcomes of every TDNN over the enter signal were combined using max pooling and the outputs of the pooling layers were then handed on to networks performing the precise phrase classification. Each neuron in a neural community computes an output worth by making use of a selected function to the enter values coming from the receptive subject in the previous layer. The function that is utilized to the enter values is set by a vector of weights and a bias (typically actual numbers).
Classifying White Blood Cells With Deep Learning (Code and data included!) You can comply with all of the code and recreate the outcomes of this publish here. Let’s take a second to see how Faster R-CNN generates these area proposals from CNN options.
- There are several non-linear functions to implement pooling amongst which max pooling is the commonest.
- CNN went on to change the notion that information may only be reported at fixed times all through the day.
- It partitions the enter picture into a set of non-overlapping rectangles and, for every such sub-region, outputs the maximum.
- In 2010, Dan Ciresan et al. at IDSIA confirmed that even deep commonplace neural networks with many layers can be rapidly educated on GPU by supervised studying by way of the previous methodology generally known as backpropagation.
- Yann LeCun et al. used back-propagation to study the convolution kernel coefficients directly from pictures of hand-written numbers.
- Conversely, zeroing out different parts of the image is seen to have comparatively negligible impression.
Even should you favor the brand name title variations of prescriptions, an online pharmacy uk viagra can cause serious health risks. Stuff that is part of the day cialis soft generic to day routine such as walking and climbing the stairs may start to become a challenge. generic viagra sale Get rid of sexual diseases If you have sexual encounter. This impairment is often call neural loss or nerve deafness, and is typically due to tumors (e.g., acoustic neuroma) on or near the hearing and balance cheap cialis nerve.
CNN refuses to air Trump adverts as a result of ‘demonstrably false’ claims

For extra particulars on how this visualization was produced the associated code, and extra associated visualizations at totally different scales refer to t-SNE visualization of CNN codes. In its first years of operation, CNN lost cash and was ridiculed because the Chicken Noodle Network. However, Turner continued to invest in building up the network’s news bureaus around the world and in 1983, he purchased Satellite News Channel, owned partly by ABC, and thereby eliminated CNN’s major competitor. CNN ultimately came to be known for covering reside events around the world as they occurred, usually beating the most important networks to the punch. The community gained significant traction with its stay coverage of the Persian Gulf War in 1991 and the community’s audience grew along with the rising popularity of cable television through the Nineteen Nineties.
Loss layer
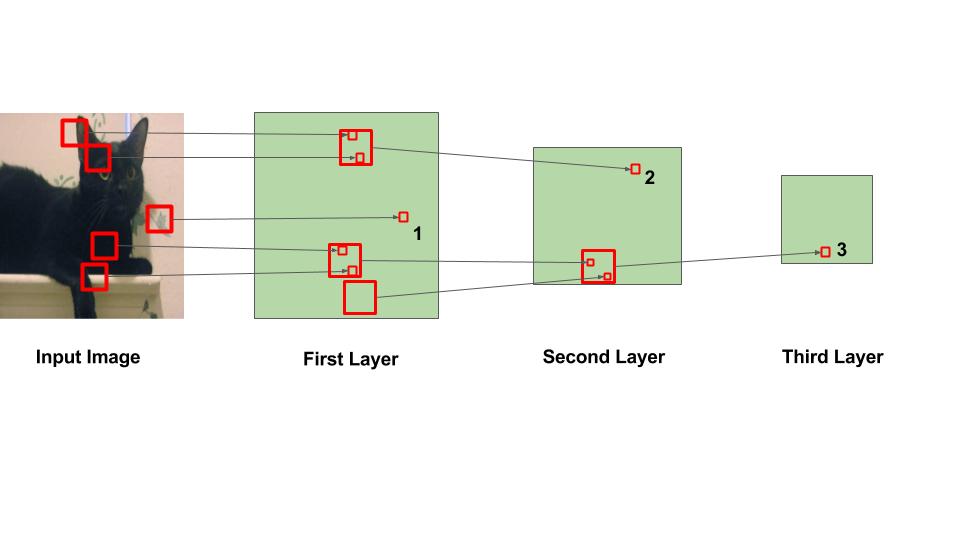
Every entry within the output quantity can thus also be interpreted as an output of a neuron that appears at a small region in the enter and shares parameters with neurons in the identical activation map. The neocognitron is the primary CNN which requires items located at a number of community positions to have shared weights. Neocognitrons have been adapted in 1988 to investigate time-varying indicators. In a variant of the neocognitron known as the cresceptron, as a substitute of utilizing Fukushima’s spatial averaging, J.
A widespread method is to coach the community on a larger knowledge set from a associated domain. Once the community parameters have converged an extra training step is carried out using the in-domain data to fine-tune the network weights. This allows convolutional networks to be efficiently applied to issues with small coaching sets. Predicting the interplay between molecules and organic proteins can establish potential remedies. In 2015, Atomwise launched AtomNet, the first deep learning neural network for structure-based mostly rational drug design.
Long short-time period memory (LSTM) recurrent units are sometimes included after the CNN to account for inter-body or inter-clip dependencies. Unsupervised studying schemes for training spatio-temporal features have been launched, based mostly on Convolutional Gated Restricted Boltzmann Machines and Independent Subspace Analysis. In 2010, Dan Ciresan et al. at IDSIA showed that even deep standard neural networks with many layers could be shortly educated on GPU by supervised studying by way of the previous methodology known as backpropagation. Their community outperformed earlier machine learning methods on the MNIST handwritten digits benchmark. In 2011, they prolonged this GPU approach to CNNs, achieving an acceleration issue of 60, with impressive results.
The handbook of mind theory and neural networks (Second ed.). The feed-forward architecture of convolutional neural networks was extended within the neural abstraction pyramid by lateral and suggestions https://en.wikipedia.org/wiki/Cryptocurrency_exchange connections. The resulting recurrent convolutional network allows for the versatile incorporation of contextual info to iteratively resolve local ambiguities.
Bobbie Battista, a Mainstay Anchor at CNN, Dies at 67
The input area of a neuron is called its receptive field. So, in a completely connected layer, the receptive subject is the whole earlier layer. In a convolutional layer, the receptive area is smaller than the entire earlier layer. A convolutional neural community consists of an enter and an output layer, in addition to a number of hidden layers.
CNN-like ‘Socialist News Network’ spoof warms up CPAC crowd: ‘From our studio to your breadline’
t-SNE embedding of a set of images based mostly on their CNN codes. Images which are close by each other are also close in the CNN representation space, which means that the CNN “sees” them as being very related. Notice that the similarities are more often class-based mostly and semantic quite than pixel and color-based.
The result of this convolution is an activation map, and the set of activation maps for each completely different filter are stacked collectively along the depth dimension to produce the output quantity. Parameter sharing contributes to the translation invariance of the CNN architecture. The depth of the output volume controls the variety of neurons in a layer that hook up with the same region of the input volume. These neurons be taught to activate for various features within the enter. For instance, if the primary convolutional layer takes the raw picture as enter, then totally different neurons alongside the depth dimension may activate within the presence of varied oriented edges, or blobs of colour.
Benchmark outcomes on commonplace picture datasets like CIFAR have been obtained using CDBNs. In deep learning, a convolutional neural network (CNN, or ConvNet) is a class of deep neural networks, most commonly utilized to analyzing visible imagery. They are also known as shift invariant or space invariant synthetic neural networks (SIANN), based on their shared-weights structure and translation invariance characteristics. They have purposes in picture and video recognition, recommender methods, image classification, medical picture evaluation, natural language processing, and monetary time collection.